TimesNet은 FFT를 이용하여 시계열 데이터의 다주기성을 주요 특징으로 삼아 학습한다는 점에 의미가 있는 모델이다. 사실 하나의 시계열 데이터는 그 안에 여러가지 요소들이 복합적으로 합쳐진 데이터 일 것이므로, 이 접근이 타당할 수도 있을 것이다. 또 일반적으로 "예측"에만 포커스를 맞추는 다른 시계열 모델들과 달리, forecast, imputation, classification, anomaly detection의 모든 작업에서 평가 하였으며, 모든 작업에서 SOTA를 달성하였다.
Introduction
많은 연구에서는 시계열의 연속성, 주기성, 추세 등과 같은 본질적 특성을 잘 반영할 수 있는 시간적 변동에 초점을 맞춘다. 그러나 실제 데이터에서는 이 변동성이 아주 복잡하여 모델링을 매우 어렵게 만든다.
RNN과 TCN의 경우 long term dependencies를 잘 포착하지 못한다. 트랜스포머 기반의 모델은 최근 더 많이 활용되지만 역시나 시간적 의존성이 복잡한 시간 패턴 속에 깊이 숨겨져 있어, 신뢰할 수 있는 의존성을 찾아내기는 어렵다.
본 연구는 복잡한 시간적 변동을 다루기 위해 다주기성이라는 새로운 차원에서 시계열을 분석한다. 실제 시계열은 보통 다주기성을 보이며, 각 주기에 대해 각 시점의 변동은 인접 영역의 시간 패턴뿐 아니라 인접 주기의 변동과도 밀접한 관련이 있다. 명확하게 하기 위해 이를 주기 내 변동과 주기 간 변동으로 명명한다. (주기 내 단기 패턴과 다른 주기의 장기 트렌드 반영, 명확한 주기성이 없는 경우 변동은 주기 내 변동이 지배)
그러나 1D 시계열로는 두 가지 다른 유형의 변동을 동시에 명시적으로 표현하기 어렵다. 따라서 본 연구에서는 시간적 변동 분석을 2D 공간으로 확장한다.
이를 바탕으로 시계열 분석을 위한 새로운 범용 모델인 TimesNet을 제안한다. TimesBlock에 의해 강화된 TimesNet은 시계열의 다주기성을 발견하고 모듈식 아키텍처에서 해당 시간적 변동을 포착할 수 있다. TimesBlock은 1D 시계열을 2D 텐서 집합으로 변환하고, 2D 공간에서 주기 내 및 주기 간 변동을 추가로 포착한다.
기여점
- 1D 시계열을 2D 시계열 공간으로 변환함으로써 주기 내 및 주기 간 변동을 동시에 표현할 수 있다.
- TimesBlock을 통해 여러 주기를 발견하고 이를 가지고 2D 변동성을 포착하는 TimesNet 제안
- 범용 기반 모델로서 5개의 주류 시계열 분석에서 일관된 최첨단 성능 달성
핵심
시계열 데이터는 여러 주기를 동시에 가짐 (ex. 주간 변동과 분기별 변동이 동시에 혼재) → 이런 여러 주기들이 상호작용하면서 복잡한 패턴이 생성됨 → 이건 1차원적 분석으로 파악하기 어려움 → 그래서 2D 차원 변동성을 분석하는 것이 중요
TimesNet
Transform 1D-variations into 2D-variations

위 그림에서 period1, 2, 3은 서로 다른 주기를 나타낸다. 즉 독립적으로 2D 형태를 구성한다. 또한 서론의 주기 내 변동성은 intraperiod이고, 주기 간 변동성은 interperiod이다. C개의 변수를 기록한 T 길이의 시계열에서 우선 주기 간 변동을 표현하기 위해 주기를 발견해야 한다. FFT를 통해서 주파수 도메인에서 시계열을 분석한다.
$A = \text{Avg}\left(\text{Amp}\left(\text{FFT}(X_{1D})\right)\right) , \; \{ f_1, \cdots, f_k \} = \underset{f_* \in \{ 1,\cdots,[\frac{T}{2}] \}} {\arg\text{Topk}}(A) ,\quad p_i = \left\lceil\frac{T}{f_i}\right\rceil, \quad i \in \{1, \cdots, k\}$
- $\text{FFT}(X_{1D})$ : 시계열을 FFT 변환을 수행
- $\text{Avg}(\text{Amp}(\text{FFT}(X_{1D})))$ : FFT 변환 결과의 각 주파수에 대해서 여러 변수에 대해서 평균 계산 → A : 각 주파수별 중요도를 나타내는 벡터
- $\text{Topk}(A)$ : 상위 $k$개의 주파수 인덱스 선택
- $p_i = \left\lceil\frac{T}{f_i}\right\rceil$ : 각 주파수에 대응하는 주기 길이 계산 (전체 시계열 / 주파수)
주파수 도메인의 희소성을 고려하고, 무의미한 고주파에 의한 노이즈를 피하기 위해 상위 k개의 진폭값만 선택하고 가장 중요한 주파수를 비정규화된 진폭과 함께 얻는다. (K는 하이퍼파라미터)
$\mathrm{X}{2D}^i=\text{Reshape}{p_i, f_i}(\text{Padding}(\mathrm{X_{1D}})), \quad i\in\{1, ..., k\}$
$\mathrm{X}_{1D}$의 길이가 $(p_i \times f_i)$로 나누어 떨어지지 않을 경우를 대비하여 시계열 끝 부분에 0을 추가하여 길이를 맞춤
(예를 들어 설명하자면 아래 과정으로 이해할 수 있다)
과거 8개의 데이터로 미래 8개의 데이터를 예측한다고 할 때, 총 16개의 데이터가 필요
그런데 여기서 추출된 주파수의 주기가 6이라면 6의 정수배인 18이 되도록 뒤에 2개를 0으로 패딩
그러면 사실 처음 데이터의 차원은 (Batch, 16, d_model) 이였는데 (Batch, 18, d_model)로 바뀌고
2차원 변환을 위해서 (Batch, 3, 6, d_model)로 변환 (18은 주기 6이 3회 반복된 것이므로)
결과적으로 18이라는 1D 데이터가 3x6의 2D 데이터로 모델에 들어감 (이 부분이 아래 그림의 초록 박스, 2D로 reshape 되는 과정)

결과적으로 이 2D 텐서는 두 가지 유형의 지역성을 가져온다.
- 인접한 시점들 사이의 지역성 : 주기 내 변동성 (Intraperiod)
- 인접한 주기들 사이의 지역성 : 주기 간 변동성 (Interperiod)
TimesBlock
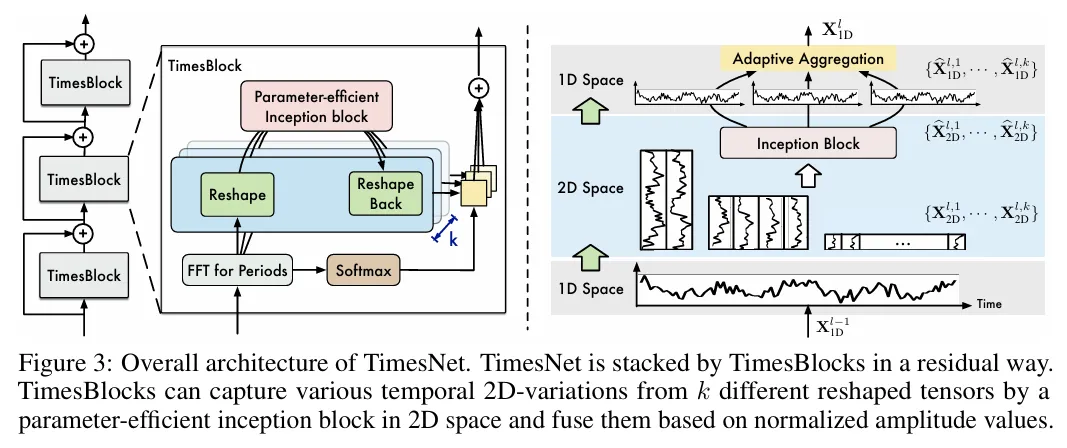
TimesBlock은 residual connection 방식으로 구성된다. 가장 우측 그림의 입력이 되는 $\mathrm{X}_{1D}^{l-1}$은 첫 번째 입력층 ($1D$)에서의 $l-1$은 $\mathrm{X}$가 d_model로 임베딩 된 상태에서의 레이어 번호를 의미한다.
Capturing temporal 2D-variations
위의 예시에서 설명한 것 처럼 2D 텐서를 얻으면(Figure2의 초록색 박스 부분이 Figure3의 우측 아래 1D → 2D가 되는 과정), 이를 inception 블록으로 처리한다. 이 때, 서로 다른 주기에 대해 모두 같은 inception 블록을 사용하여 파라미터가 효율적으로 적용된다. Figure3 우측의 2D Space에는 3개의 주기가 선택된 것으로 나타나며 이 3개 주기의 2D 텐서는 하나의 inception 블록으로 처리된다. Inception 블록을 통해 $\mathrm{\hat{X}}$을 얻고, 이것을 다시 1D로 변환한다. 그리고 패딩된 부분을 제거한다.
Adaptive aggregation
결과적으로 여러 주기의 1D 표현을 얻게 되는데, 이를 통합할 필요가 있다. Autoformer의 Auto correlation에서 영감을 받아, 진폭 값들에 softmax를 적용하여 각 주기별 정규화된 가중치를 얻고, 이를 결과물인 1D 표현과 곱하여 모든 주기에 대해 가중합을 계산하여 최종적인 1D 표현을 얻는다.
Generality in 2D vision backbones
Inception 블록은 다른 컴퓨터 비전 백본으로 대체할 수 있다. (ex. ResNet, ResNeXt, ConvNeXt, 어텐션 기반 모델들…)
시간적 2차원 변동성을 통해 시계열 분석이 컴퓨터 비전 커뮤니티의 발전을 활용할 수 있다.
표현 학습을 위해 더 강력한 2차원 백본을 사용할 수 있으나, 성능과 효율성을 모두 고려하여 inception 기반으로 주요 실험을 수행한다.
===임베딩===
논문에서는 다루고 있지 않지만, 실제 코드 구현에서 입력 시계열을 모델에 넣을 수 있게 변환해주는 임베딩 부분이 존재한다. 입력 시계열 $\mathrm{x}$는
$\mathrm{x} = \text{value embedding}(\mathrm{x}) + \text{positional embedding}(\mathrm{x})$
형태로 변환되어 모델에 들어간다.
- value embedding
예를 들어 입력 시계열의 shape이 [32, 152, 3] 이라고 가정한다. 이 때, 이 shape은 [배치 사이즈, 과거 데이터 시퀀스 길이, 변수 수] 를 의미한다.
1d Conv를 통해 [32, 152, 512]로 변환하는데, 512는 d_model, 사용자가 지정하는 하이퍼파라미터이다. (논문에선 512 사용) 이 과정을 통해 channel mixing 효과를 가질 수 있다. - positional embedding
시퀀스 길이인 152의 차원에 따라 위치 정보를 임베딩하기 때문에 [1, 152, 512] 형태로 변환
이 두 가지 임베딩이 합쳐져서 모델의 인풋으로 들어간다.
Experiments
결과는 당연히 본인들이 모든 영역에서 SOTA를 달성했다고 하니 생략하고...
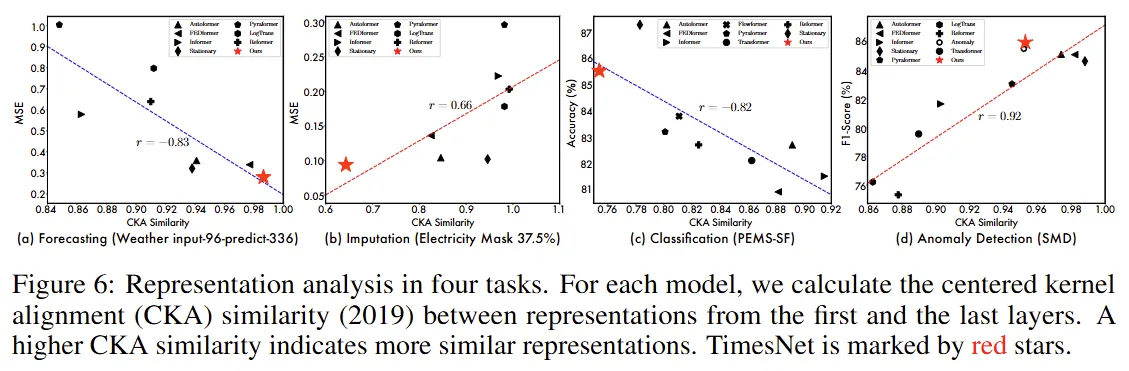
Representation Analysis 부분을 살펴보면 CKA 유사도 라는 것이 나온다.
CKA(Centered Kernel Alignment) 유사도란 신경망의 서로 다른 레이어 사이의 표현이 얼마나 유사한지 측정하는 지표이다.
- 높은 CKA 유사도
- 서로 다른 레이어의 표현이 매우 비슷
- 각 레이어가 비슷한 특징을 학습하여 시계열 예측, 이상 탐지 등 low-level 특징 학습에 적합
- 낮은 CKA 유사도
- 서로 다른 레이어의 표현이 많이 다름
- 각 레이어가 다른 수준의 특징을 학습하여 계측정 특징 학습에 적합 → 분류, 보간
그런데 아래 Figure6을 보면 TimesNet은 각 task에 맞게 아주 적합한 표현 학습 형태를 보인다. 반면 FEDformer의 경우 예측과 이상 탐지는 잘 작동하지만, 계층적 표현 학습을 하지 못하여 보간과 분류에서 성능이 저조하다.



댓글