퍼셉트론 (perceptron)
퍼셉트론이란?
퍼셉트론은 Frank Rosenblatt가 1957년에 고안한 알고리즘이다. 다수의 신호를 입력받아 하나의 신호를 출력하는 feedforward 형태의 네트워크로 선형분류기로도 볼 수 있다. 인간의 뉴런은 dendrite를 통해 입력 받은 신호가 어떠한 임계치(threshlod)를 넘어서면 활성화(activate)되는 동작을 하는데 이 현상을 컴퓨터로 구현한 것이 퍼셉트론이다.

퍼셉트론의 개념을 도식화하면 다수의 입력 값 x가 있을 때, 중요도에 따라 각각의 입력 값에 w(weight)를 곱해 준 후 bias를 더한다. 그 결과 값들을 모두 더하여 하나의 값(z)으로 만든다. 마지막으로 z값을 0과 1로 반환해 줄 수 있는 활성 함수(Activation funtion)에 넣어 예측값을 구한다. 활성 함수는 뉴런이 어떤 임계치를 넘어서면 활성화 되는 것을 구현한 것이다. 따라서 활성 함수가 적용되기 전까지의 값인 z는 linear 형태이지만, 활성 함수가 적용 된 후에는 nonlinear 형태가 된다.
논리 회로 (Logic Gate)
퍼셉트론이 컴퓨터에서 어떻게 작동하는지 이해하기 위해 논리 회로에 대해 알 필요가 있다. 논리 회로는 하나 이상의 binary한 input들을 가지고 단일 binary output을 출력하는 Boolean function 역할을 수행하는 장치이다. 그 중 AND Gate에 대해서 살펴보면 두 입력이 모두 1일 때만 1을 출력하고, 그 외에는 0을 출력하는 회로이다.
AND Gate 구현 (Python)
위의 AND Gate가 퍼셉트론과 같이 동작하는 과정을 파이썬으로 구현해보면 다음과 같다.
def AND(x1, x2):
w1, w2, theta = 0.5, 0.5, 0.7
z = x1*w1 + x2*w2
if z <= theta:
return 0
else:
return 1
# 결과값
print(AND(0, 0)) # 0
print(AND(1, 0)) # 0
print(AND(0, 1)) # 0
print(AND(1, 1)) # 1가중치 w와 임계치 theta가 함수 내에서 정의되고, 입력 값 x에 따라 계산된 z값이 임계값 theta를 넘으면 1을 반환하고 그렇지 않으면 0을 반환한다.
퍼셉트론의 한계
동일한 방식으로 NAND, OR Gate를 모두 구현할 수 있으나 XOR Gate, 두 입력 값이 같을 때는 0이고 두 입력 값이 다를 때는 1을 반환할 경우에는 논리 회로를 구현할 수 없다.
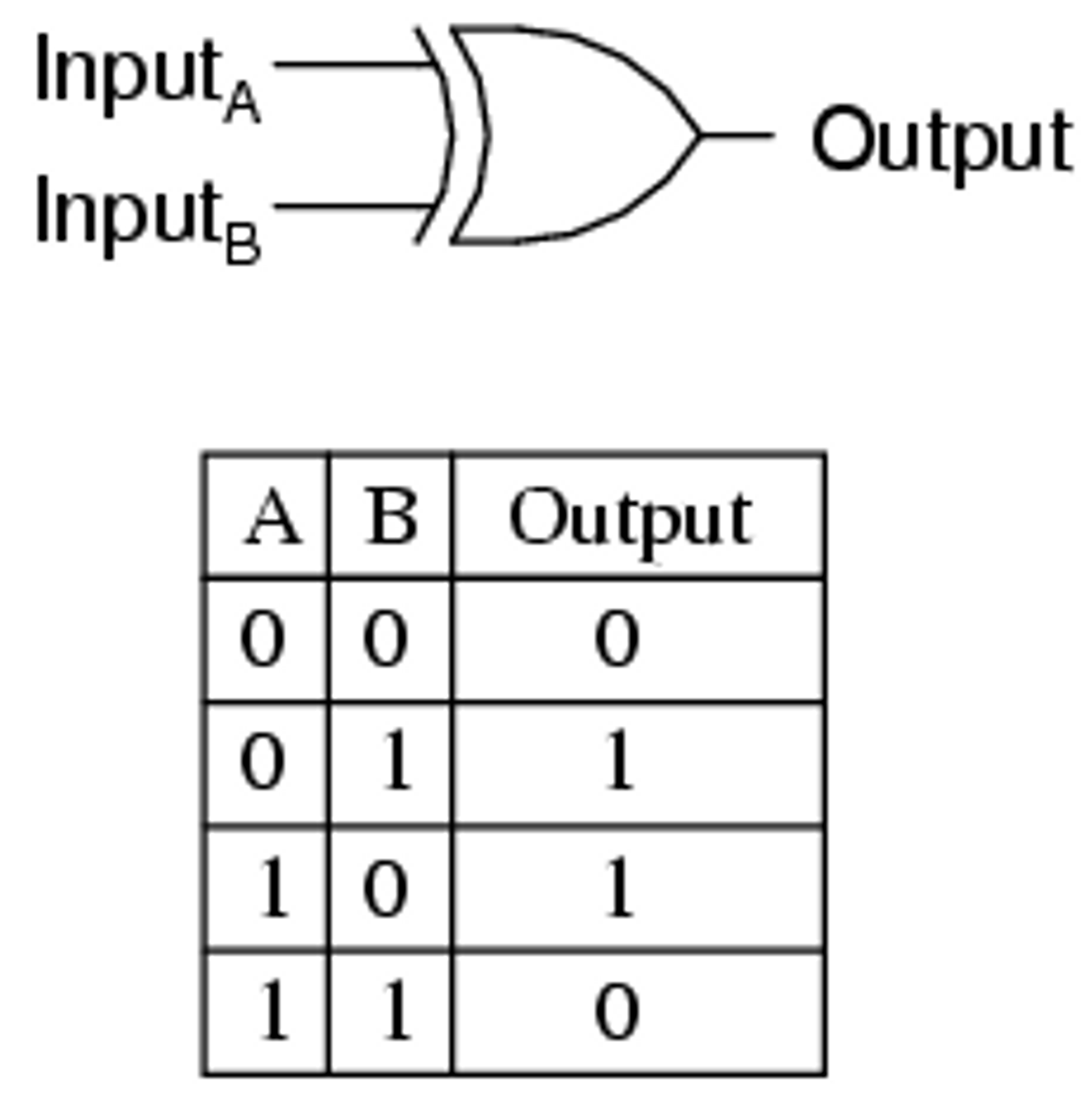
1969년 Minsky와 Papert는 이러한 XOR Gate의 문제를 제기하며 퍼셉트론에 대한 한계를 이야기 했다. 그러나 AND, NAND, OR Gate를 조합하면 XOR Gate를 만들 수 있다. 즉, single-layer가 아닌 multi-layer를 통해서 퍼셉트론의 한계를 극복할 수 있다.
Multi-Layer Perceptron (MLP)
XOR Gate 문제와 같이 퍼셉트론의 한계를 극복하기 위해 Layer를 여러개 쌓아올린 MLP가 등장하였다. 퍼셉트론과 다르게 Input / Output Layer 사이에 Hidden Layer가 존재해 여러가지 조합이 가능해진다.

MLP란?
- 딥러닝의 가장 기본적인 모델
- Feedforward, 한 방향으로 진행하는 형태의 네트워크
- Input Layer, Output Layer, 그리고 여러개의 Hidden Layer(은닉층)로 구성됨
Input node를 제외하면, 각각의 node들은 뉴런(퍼셉트론)인데 이것은 활성 함수를 통해 발생한 값으로 nonlinear 형태이다. 일반적인 경우 Layer 수를 말할 때에는 Hidden Layer + Output Layer 수로 말하며, 이 Layer가 많을수록 더 정교하게 분류가 가능하다.
MLP 구현 (Python)
Activation Function은 Sigmoid 함수(11+e−x)를 사용 하였다. Activation Function, 즉 활성함수는 다시 포스팅하겠지만 우선은 신호가 전달을 시작하는 임계치라고 이해한다.
def sigmoid(x):
return 1 / (1+np.exp(-x))
def init_network():
# dict 생성
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = a3
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y)
# 0.31682708 0.69627909
참고 :
[1] 도서 - 밑바닥 부터 시작하는 딥러닝, 사이토 고키
[2] 유튜브 - 오승상 딥러닝
'AI > Deep Learning' 카테고리의 다른 글
| Activation function, 활성함수의 특징 (0) | 2024.11.30 |
|---|---|
| MLE 최대화가 Cross entropy 최소화와 같은 효과인 이유 (0) | 2024.11.30 |
| PSNR과 SSIM 설명 (1) | 2024.02.06 |
| AutoEncoder(AE) (0) | 2023.08.25 |
| Deep Neural Network (DNN) (0) | 2023.05.17 |
댓글