해당 논문은 CVPR 2021에서 소개된 논문으로 SR3 라는 이름으로 알려져 있다. DDPM을 통해 Super Resolution task를 수행하는 방법에 대해서 소개한다. 상세한 논문의 내용보다는 개념 위주로 간단하게 포스팅한다.
1. Introduction
Deep generative model들은 좋은 이미지 생성 결과들을 보여주었다. 그러나 자기 회귀는 비용이 너무 많이 들고, Normalizaing Flow와 VAE는 품질이 종종 좋지 않다. GAN은 불안정성과 mode collapse 문제가 따라다닌다. 따라서 신중하게 설계된 regularization과 optimization 기법이 필요하다.
DDPM 및 denoising score matching에서 영감을 받은 SR3를 제안한다. 핵심은 다양한 수준의 노이즈를 반복적으로 제거하는 목적으로 훈련된 UNet 구조이다. 특정 도메인(예: 얼굴)에 초점을 맞춘 기존 작업과 달리, 우리는 SR3가 얼굴과 자연 이미지 모두에 효과적임을 보여준다.
기존의 score인 PSNR이나 SSIM은 high frequency details 상황에서 인간의 선호도를 잘 반영하지 못하므로, 2AFC(2가지 대안 강제 선택) 패러다임을 채택한다.
본 논문을 이해하기 위해서는 DDPM에 관하여 필수적으로 이해하여야 한다. DDPM에 관한 내용은 이전 포스팅에서 살펴 볼 수 있다.
2024.01.11 - [Studies/논문리뷰] - Diffusion model의 이해 (DDPM: Denoising Diffusion Probabilistic Models)
2. 방법론
SR3는 DDPM에 기반하여 이해할 수 있다. SR3에서는 첫 이미지를 $y_0$로 표시하는데 $y_0$는 $x$로부터 생성된 데이터이다. 즉 $y_0\sim p(y|x)$로 표현할 수 있다. 여기서 $x$는 원본 데이터를 뜻하며, $y$는 원본 데이터로부터 생성된 Low-Resolution 이미지, 즉 저화질 이미지를 나타낸다. 이 저화질 이미지에서부터 학습이 시작된다. DDPM과 동일하게 이 저화질 이미지에 점진적으로 노이즈를 주입하면 $y_0$가 $y_T$에 이르고, 이 때의 노이즈는 표준 정규 분포에 근사된다. DDPM과 비교하여 살펴보면 아래와 같다.

다시 한 번 DDPM과의 차이를 비교해보면 아래처럼 표현할 수 있을 것 같은데, 여기서 특이할만한 점은 $y_0$이다. 원본에서 저화질 이미지인 $y_0$를 생성할 때 Bicubic 방법으로 이미지를 downsampling 하는 것이다. 또한 추론 과정에서도 "노이즈 이미지"와 그 "노이즈 이미지의 원본"인 $x_t, x_0$의 joint distribution을 가진 DDPM과 달리, "노이즈 이미지"와 그 "노이즈 이미지의 원본을 추출한 원본"인 $y_t, x$의 joint distirubion을 구한다는 점에서 차이가 있다.

조금 더 직관적으로 보면 High Resolution, 즉 원본 이미지인 고해상도 이미지에서 bicubic 방법으로 저해상도 이미지를 만든다. 이 때 실제 코드에서는 이 저해상도 이미지를 resize하여 원본 이미지인 고해상도 이미지와 크기를 맞춰서 두 feature를 concat하여 diffusion 모델에 학습시키는 과정을 포함한다.

이 외에 모든 과정은 DDPM과 동일하다.
3. 결과
Automated metrics
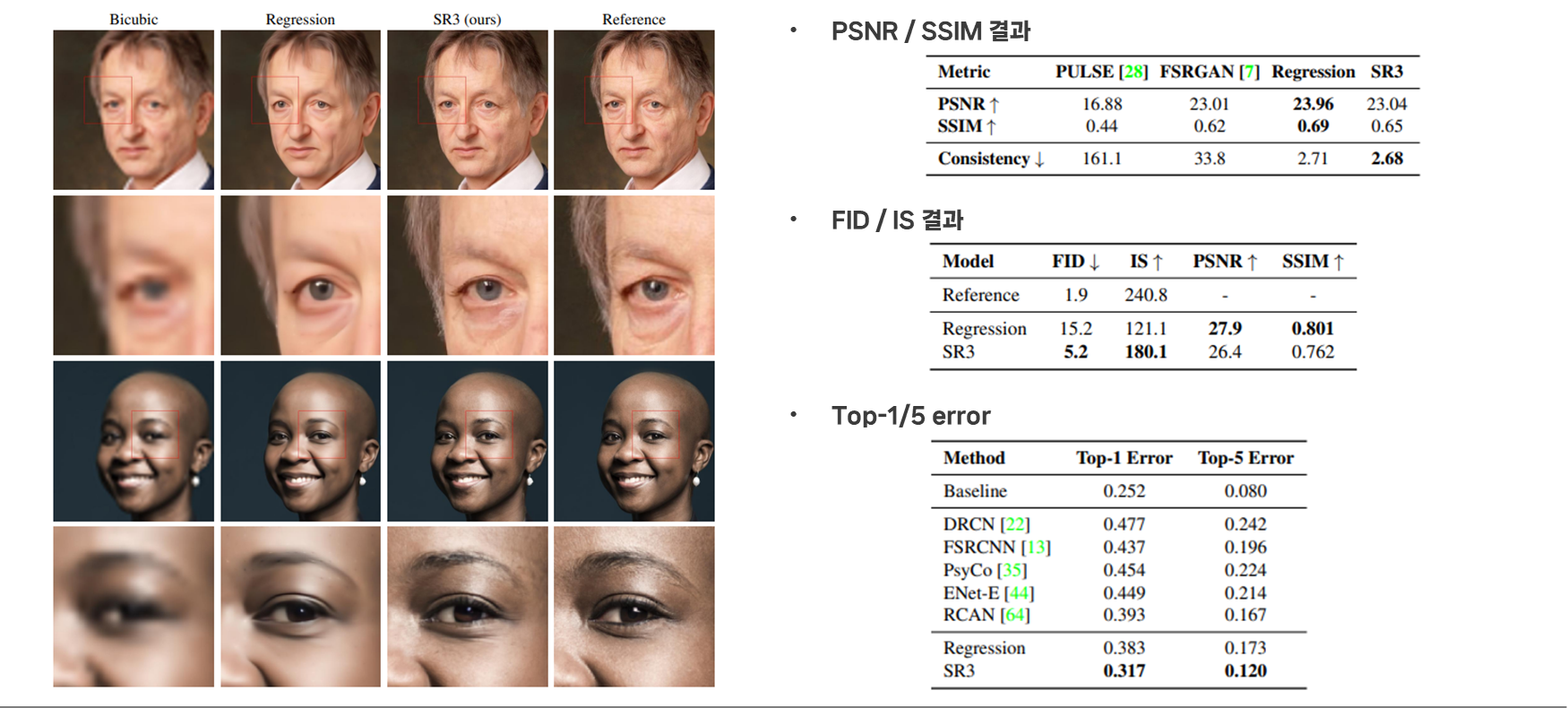
결과를 보면 Super resolution을 평가하는 전통적 지표인 PSNR과 SSIM은 기존의 모델들이 더 우수함을 보이는 것을 알 수 있다. 그러나 FID에서는 SR3가 더 좋은 결과를 보이는데, 이는 기존의 평가 방법들이 high frequency detail들을 반영하지 못하기 때문이다.
* High frequence란 고주파 영역, 즉 이미지의 변동이 큰 가장자리 같은 부분을 의미한다. 반대로 low frequency 영역은 배경과 같이 큰 변동이 없는 영역을 뜻한다.
Human evaluation
따라서 서두에 소개한 것처럼 2AFC 평가를 하는데, 2 가지 대안 중 사람이 투표하게 하는 정성적 평가라고 이해할 수 있다.
- 첫 번째 질문은 LR 이미지, 즉 저해상도 이미지를 얼마나 더 잘 표현했는가에 관한 질문이고,
- 두 번째는 어느 것이 더 실제 이미지 같은가에 관한 질문이다.
그것을 Fool rate (Ground truth가 아닌 모델이 생성한 이미지를 선택할 확률) 로 표현하는데, SR3의 선택이 다른 방법론들을 압도했다. 즉 정량적 평가로는 좋지 않게 나왔으나, 실제로 눈으로 보기에도 SR3가 더 우수하며 이것을 설문조사 했을 때에도 SR3가 우수했다는 것을 나타내고자 하는 것 같다.

'논문리뷰 > Diffusion models' 카테고리의 다른 글
| Diffusion model의 이해 (DDPM: Denoising Diffusion Probabilistic Models) (2) | 2024.01.11 |
|---|

댓글